
Nucleic acid sequence
This article needs additional citations for verification. (March 2014) |
A nucleic acid sequence is a succession of
The sequence represents genetic information. Biological
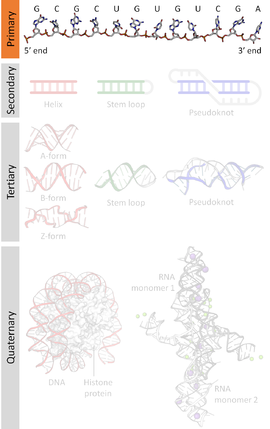
Nucleic acids also have a secondary structure and tertiary structure. Primary structure is sometimes mistakenly referred to as "primary sequence". However there is no parallel concept of secondary or tertiary sequence.
Nucleotides

Nucleic acids consist of a chain of linked units called nucleotides. Each nucleotide consists of three subunits: a phosphate group and a sugar (ribose in the case of RNA, deoxyribose in DNA) make up the backbone of the nucleic acid strand, and attached to the sugar is one of a set of nucleobases. The nucleobases are important in base pairing of strands to form higher-level secondary and tertiary structures such as the famed double helix.
The possible letters are A, C, G, and T, representing the four
One sequence can be complementary to another sequence, meaning that they have the base on each position in the complementary (i.e., A to T, C to G) and in the reverse order. For example, the complementary sequence to TTAC is GTAA. If one strand of the double-stranded DNA is considered the sense strand, then the other strand, considered the antisense strand, will have the complementary sequence to the sense strand.
Notation
While A, T, C, and G represent a particular nucleotide at a position, there are also letters that represent ambiguity which are used when more than one kind of nucleotide could occur at that position. The rules of the International Union of Pure and Applied Chemistry (
For example, W means that either an adenine or a thymine could occur in that position without impairing the sequence's functionality.
| Symbol[2] | Meaning/derivation | Possible bases | Complement | ||||
|---|---|---|---|---|---|---|---|
| A | Adenine | A | 1 | T (or U) | |||
| C | Cytosine | C | G | ||||
| G | Guanine | G | C | ||||
| T | Thymine | T | A | ||||
| U | Uracil | U | A | ||||
| W | Weak | A | T | 2 | W | ||
| S | Strong | C | G | S | |||
| M | aMino | A | C | K | |||
| K | Keto | G | T | M | |||
| R | puRine | A | G | Y | |||
| Y | pYrimidine | C | T | R | |||
| B | not A (B comes after A) | C | G | T | 3 | V | |
| D | not C (D comes after C) | A | G | T | H | ||
| H | not G (H comes after G) | A | C | T | D | ||
| V | not T (V comes after T and U) | A | C | G | B | ||
| N | any Nucleotide (not a gap) | A | C | G | T | 4 | N |
| Z | Zero | 0 | Z | ||||
These symbols are also valid for RNA, except with U (uracil) replacing T (thymine).[1]
Apart from adenine (A), cytosine (C), guanine (G), thymine (T) and uracil (U), DNA and RNA also contain bases that have been modified after the nucleic acid chain has been formed. In DNA, the most common modified base is
- Example of comparing and determining the % difference between two nucleotide sequences
- AATCCGCTAG
- AAACCCTTAG
Given the two 10-nucleotide sequences, line them up and compare the differences between them. Calculate the percent difference by taking the number of differences between the DNA bases divided by the total number of nucleotides. In this case there are three differences in the 10 nucleotide sequence. Thus there is a 30% difference.
Biological significance
In biological systems, nucleic acids contain information which is used by a living
The
Sequence determination

DNA sequencing is the process of determining the
RNA is not sequenced directly. Instead, it is copied to a DNA by reverse transcriptase, and this DNA is then sequenced.
Current sequencing methods rely on the discriminatory ability of DNA polymerases, and therefore can only distinguish four bases. An inosine (created from adenosine during RNA editing) is read as a G, and 5-methyl-cytosine (created from cytosine by DNA methylation) is read as a C. With current technology, it is difficult to sequence small amounts of DNA, as the signal is too weak to measure. This is overcome by polymerase chain reaction (PCR) amplification.
Digital representation

Once a nucleic acid sequence has been obtained from an organism, it is stored in silico in digital format. Digital genetic sequences may be stored in sequence databases, be analyzed (see Sequence analysis below), be digitally altered and be used as templates for creating new actual DNA using artificial gene synthesis.
Sequence analysis
Digital genetic sequences may be analyzed using the tools of bioinformatics to attempt to determine its function.
Genetic testing
The DNA in an organism's
Genetic testing identifies changes in chromosomes, genes, or proteins.[6] Usually, testing is used to find changes that are associated with inherited disorders. The results of a genetic test can confirm or rule out a suspected genetic condition or help determine a person's chance of developing or passing on a genetic disorder. Several hundred genetic tests are currently in use, and more are being developed.[7][8]
Sequence alignment
In bioinformatics, a sequence alignment is a way of arranging the sequences of
Sequence motifs
Frequently the primary structure encodes motifs that are of functional importance. Some examples of sequence motifs are: the C/D[12] and H/ACA boxes[13] of
Sequence entropy
In bioinformatics, a sequence entropy, also known as sequence complexity or information profile,[17] is a numerical sequence providing a quantitative measure of the local complexity of a DNA sequence, independently of the direction of processing. The manipulations of the information profiles enable the analysis of the sequences using alignment-free techniques, such as for example in motif and rearrangements detection.[17][18] [19]
See also
- Gene structure
- Nucleic acid structure determination
- Quaternary numeral system
- Single-nucleotide polymorphism (SNP)
References
- ^ PMID 2417239.
- ^ Nomenclature Committee of the International Union of Biochemistry (NC-IUB) (1984). "Nomenclature for Incompletely Specified Bases in Nucleic Acid Sequences". Retrieved 2008-02-04.
- ^ "BIOL2060: Translation". mun.ca.
- ^ "Research". uw.edu.pl.
- PMID 1557408.
- ^ "What is genetic testing?". Genetics Home Reference. 16 March 2015. Archived from the original on 29 May 2006. Retrieved 19 May 2010.
- ^ "Genetic Testing". nih.gov.
- ^ "Definitions of Genetic Testing". Definitions of Genetic Testing (Jorge Sequeiros and Bárbara Guimarães). EuroGentest Network of Excellence Project. 2008-09-11. Archived from the original on February 4, 2009. Retrieved 2008-08-10.
- ISBN 0-87969-608-7.
- PMID 11337480.
- S2CID 30962295.
- PMID 9649444.
- PMID 9106664.
- S2CID 4162567.
- PMID 3313277.
- S2CID 9982829.
- ^ PMID 24278218.
- PMID 25984837.
- PMID 12050064.
External links
| Authority control databases: National |
|---|