
Search results
There is a page named "String-searching algorithm" on Wikipedia
- computer science, string-searching algorithms, sometimes called string-matching algorithms, are an important class of string algorithms that try to find...18 KB (2,005 words) - 14:01, 7 April 2024
- In computer science, the Rabin–Karp algorithm or Karp–Rabin algorithm is a string-searching algorithm created by Richard M. Karp and Michael O. Rabin (1987)...14 KB (1,975 words) - 15:46, 18 April 2024
 algorithm is a string-searching algorithm invented by Alfred V. Aho and Margaret J. Corasick in 1975. It is a kind of dictionary-matching algorithm that...8 KB (984 words) - 15:57, 4 June 2024
algorithm is a string-searching algorithm invented by Alfred V. Aho and Margaret J. Corasick in 1975. It is a kind of dictionary-matching algorithm that...8 KB (984 words) - 15:57, 4 June 2024- the Boyer–Moore string-search algorithm is an efficient string-searching algorithm that is the standard benchmark for practical string-search literature...35 KB (4,804 words) - 04:25, 6 May 2024
- see String-searching algorithm which has detailed analysis of other string searching algorithms. Horspool, R. N. (1980). "Practical fast searching in strings"...8 KB (1,011 words) - 14:49, 30 January 2023
- Knuth–Morris–Pratt algorithm (or KMP algorithm) is a string-searching algorithm that searches for occurrences of a "word" W within a main "text string" S by employing...33 KB (4,068 words) - 06:35, 28 April 2024
 In computer science, approximate string matching (often colloquially referred to as fuzzy string searching) is the technique of finding strings that match...14 KB (1,666 words) - 12:08, 21 June 2024
In computer science, approximate string matching (often colloquially referred to as fuzzy string searching) is the technique of finding strings that match...14 KB (1,666 words) - 12:08, 21 June 2024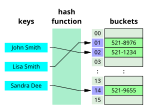 database indexes. Search algorithms can be classified based on their mechanism of searching into three types of algorithms: linear, binary, and hashing...12 KB (1,574 words) - 12:05, 9 June 2024
database indexes. Search algorithms can be classified based on their mechanism of searching into three types of algorithms: linear, binary, and hashing...12 KB (1,574 words) - 12:05, 9 June 2024- In computer science, the two-way string-matching algorithm is a string-searching algorithm, discovered by Maxime Crochemore and Dominique Perrin in 1991...9 KB (1,135 words) - 13:16, 14 May 2024
- Raita algorithm is a string searching algorithm which improves the performance of Boyer–Moore–Horspool algorithm. This algorithm preprocesses the string being...5 KB (697 words) - 17:11, 27 May 2023
- bitap algorithm (also known as the shift-or, shift-and or Baeza-Yates-Gonnet algorithm) is an approximate string matching algorithm. The algorithm tells...10 KB (1,262 words) - 23:44, 1 July 2024
 the theory of algorithms and data structures used for string processing. Some categories of algorithms include: String searching algorithms for finding...41 KB (4,976 words) - 22:43, 12 May 2024
the theory of algorithms and data structures used for string processing. Some categories of algorithms include: String searching algorithms for finding...41 KB (4,976 words) - 22:43, 12 May 2024- Commentz-Walter algorithm is a string searching algorithm invented by Beate Commentz-Walter. Like the Aho–Corasick string matching algorithm, it can search...7 KB (789 words) - 08:09, 25 January 2024
- Difference Algorithm)Matching Algorithms. Oxford University Press. ISBN 9780195354348. Masek, William J.; Paterson, Michael S. (1980), "A faster algorithm computing string edit...35 KB (4,253 words) - 16:43, 28 December 2023
- Longest common substring (section Algorithms)Algorithm Implementation/Strings/Longest common substring In computer science, a longest common substring of two or more strings is a longest string that...8 KB (1,063 words) - 07:23, 3 May 2024
- Strother Moore invented the Boyer–Moore string-search algorithm, a particularly efficient string searching algorithm, in 1977. He and Moore also collaborated...3 KB (225 words) - 19:03, 2 January 2024
- process of searching for patterns in compressed data with little or no decompression. Searching in a compressed string is faster than searching an uncompressed...4 KB (510 words) - 23:18, 19 December 2023
- String mining)sequence mining problems can be classified as string mining which is typically based on string processing algorithms and itemset mining which is typically based...9 KB (1,122 words) - 18:28, 11 December 2023
- Pattern matching (section Example string patterns)any value, but does not bind the value to any name. Algorithms for matching wildcards in simple string-matching situations have been developed in a number...21 KB (2,482 words) - 08:19, 26 June 2024




- less random... On this view we recognize science to be the search for algorithmic compressions. It is simplest to think of mathematics as the catalogue
- an impermissible consonant pair results: sd. In accordance with the algorithm for making lujvo, explained in Section 4.11 (p. 68), a y is inserted to
- A searching algorithm looks for a given item in a given data structure. The algorithm used depends on how the data is structured. If you have a list (or